Vroeër of later staan almal wat gereeld met kantoorprogramme werk, voor 'n tipiese taak: teks uit 'n boek, tydskrif, koerant, pamflette skandeer en dan die foto's in teksformaat vertaal, byvoorbeeld in 'n Word-dokument.
Om dit te kan doen, benodig u 'n skandeerder en 'n spesiale program om teks te herken. In hierdie artikel word die gratis eweknie van FineReader bespreek -spykerskrif (oor erkenning in FineReader - sien hierdie artikel).
Laat ons begin ...
inhoud
- 1. Kenmerke van die CuneiForm-program, funksies
- 2. Voorbeeld van teksherkenning
- 3. Herkenning van bondelteks
- 4. Gevolgtrekkings
1. Kenmerke van die CuneiForm-program, funksies
 spykerskrif
spykerskrif
U kan dit aflaai van die webwerf van die ontwikkelaar: //cognitiveforms.com/
'N Oopbron-teksherkenningsprogram. Boonop werk dit in alle weergawes van Windows: XP, Vista, 7, 8, wat dit behaag. Voeg ook die volledige Russiese vertaling van die program by!
voor:
- teksherkenning in die 20 gewildste tale ter wêreld (Engels en Russies is self by hierdie nommer ingesluit);
- Groot ondersteuning vir verskillende gedrukte lettertipes;
- kyk na die woordeboek van erkende teks;
- die vermoë om werksresultate op verskillende maniere te bespaar;
- behoud van die struktuur van die dokument;
- Groot ondersteuning en tafelherkenning.
nadele:
- ondersteun nie te groot dokumente en lêers nie (meer as 400 dpi);
- Ondersteun nie sekere soorte skandeerders direk nie (dit is nie 'n groot probleem nie; 'n spesiale skandeerderprogram is by die skandeerderbestuurder ingesluit);
- die ontwerp skyn nie (maar wie het dit nodig as die program die probleem ten volle oplos).
2. Voorbeeld van teksherkenning
Ons neem aan dat u reeds die nodige foto's vir erkenning ontvang het (daar geskandeer is, of 'n boek in pdf / djvu-formaat op die internet afgelaai het en die nodige foto's daarvan verwyder is. Hoe om dit te doen, sien hierdie artikel).
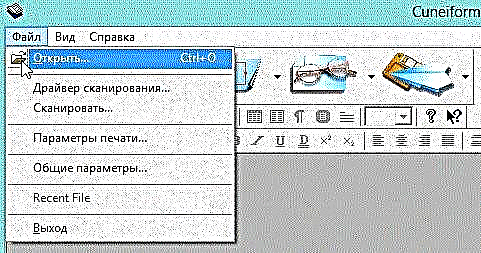
1) Open die gewenste prent in die CuineForm-program (lêer / open of "Cntrl + O").
2) Om die herkenning te begin - u moet eers verskillende gebiede kies: teks, prente, tabelle, ens. In die Cuneiform-program kan dit nie net met die hand gedoen word nie, maar ook outomaties! Om dit te doen, klik op die "uitleg" -knoppie in die boonste paneel van die venster.

3) Na 10-15 sekondes. Die program sal outomaties alle gebiede met verskillende kleure uitlig. Byvoorbeeld, 'n teksarea word in blou gemerk. Terloops, sy het alle gebiede korrek en redelik vinnig uitgelig. Ek het eerlikwaar nie so 'n vinnige en korrekte reaksie van haar verwag nie ...

4) Vir diegene wat nie die outomatiese uitleg vertrou nie, kan u die handleiding gebruik. Hiervoor is daar 'n werkbalk (sien die foto hieronder), waarmee u kan kies: teks, tabel, prent. Beweeg, vergroot / verklein die aanvanklike prent, sny die rande. In die algemeen, 'n goeie stel.

5) Nadat alle gebiede gemerk is, kan ons verder gaan erkenning. Klik hiervoor op die knoppie met dieselfde naam, soos op die onderstaande foto.

6) Letterlik binne 10-20 sekondes. U sal 'n dokument in Microsoft Word met erkende teks sien. Interessant genoeg was daar natuurlik foute in die teks vir hierdie voorbeeld, maar daar is baie min daarvan! Daarbenewens, gesien in watter onbeproke gehalte die bronmateriaal was - 'n prentjie.
Die spoed en kwaliteit is baie vergelykbaar met FineReader!

3. Herkenning van bondelteks
Hierdie programfunksie kan handig te pas kom as u nie een prentjie hoef te herken nie, maar wel op een slag. Die kortpad vir die begin van groepherkenning word meestal in die beginmenu versteek.
1) Nadat u die program oopgemaak het, moet u 'n nuwe pakket skep of 'n voorheen gebergte pakket oopmaak. Skep 'n nuwe een in ons voorbeeld.

2) In die volgende stap gee ons dit 'n naam, verkieslik een wat onthou wat ses maande later daarin gestoor is.

3) Kies die dokumenttaal (Russies-Engels) en dui aan of daar foto's en tabelle in u gescande materiaal is.

4) Nou moet u die gids waarin die lêers vir erkenning geleë is, spesifiseer. Terloops, wat interessant is, die program self vind al die foto's en ander grafiese lêers wat dit kan herken en voeg dit by tot die projek. U hoef net die ekstra te verwyder.

5) Die volgende stap is nie belangrik nie - kies wat u met die bronlêers moet doen, na herkenning. Ek beveel aan dat u die "niks doen" -kassie kies.

6) Dit bly slegs om die formaat te kies waarin die erkende dokument gestoor sal word. Daar is verskillende opsies:
- rtf - 'n lêer uit 'n woorddokument, geopen deur alle gewilde kantore (insluitend gratis, 'n skakel na programme);
- txt - teksformaat, u kan slegs teks daarin stoor; foto's en tabelle kan nie wees nie;
- htm - 'n hiperteks-bladsy, handig as u lêers vir die webwerf skandeer en herken. Ons sal dit in ons voorbeeld kies.

7) Nadat u op "Voltooi" klik het, begin die proses om u projek te verwerk.

8) Die program werk redelik vinnig. Na herkenning sal 'n oortjie met htm-lêers voor u verskyn. As u op so 'n lêer klik, begin 'n blaaier, waar u die resultate kan sien. Terloops, die pakkie kan gestoor word vir verdere werk daarmee.

9) Soos u kan sien, die resultate die werk is baie indrukwekkend. Die program het die prent maklik herken, en onder die teks is dit maklik herken. Ondanks die feit dat die program gratis is, is dit oor die algemeen super!


4. Gevolgtrekkings
As u dikwels nie dokumente skandeer en herken nie, dan is dit waarskynlik nie sin om die FineReader-program te koop nie. Die meeste take word maklik deur CuneiForm hanteer.
Aan die ander kant het sy ook nadele.
Eerstens is daar te min instrumente om die resultaat te redigeer en na te gaan. Tweedens, as u baie foto's moet herken, is dit in FineReader gemakliker om alles in die kolom aan die regterkant in die kolom regstreeks te sien: verwyder vinnig onnodige foto's, maak regstellings, ens. En derdens verloor CuneiForm as erkenning op dokumente: Ek moet die dokument in gedagte hou - foute redigeer, leestekens, aanhalingstekens, ens.
Dit is alles. Ken u enige ander waardige program vir gratis teksherkenning?